
개요
이번 글에서는 Grok Classfication을 이용한 데이터 소스 분석과 Athena에 로그까지 찍어 볼 것입니다. classification은 글루 크롤러에서 스키마, 파티션 등을 나누는 등 중요한 역할을 합니다.
Grok이란?
Grok은 ELK 스택에서 제공하는 Losgstach 데이터를 정규식으로 바꾸어 줍니다. 이러한 GORK은 다음고 같은 형식으로 사용할 수 있습니다.
${정규 패턴명:사용자의 필드}저희는 AWS의 s3 -> glue의 과정에서 이 데이터를 정규식으로 반환해주기 위하여 이 GROK을 Glue crawler를 통하여 이용할 것입니다.
Glue Classifiers & 데이터베이스 생성하기
먼저 AWS 콘솔에서 Glue -> Databases로 이동하여 데이터베이스를 만들어줍니다.

그리고 왼쪽 탭 아래에 있는 Classifiers로 들어가 줍니다.

위에서 설명한 것과 같이 Classifiers는 S3에 저장되어있는 데이터를 정규화하여 읽고 바꾸어주는 역할을 합니다.
Grok에서 아파치 웹 서버 로그는 ${COMBINEDAPACHELOG}와 같이 처리할 수 있습니다.
때문에 다음과 같이 Classifier를 생성해줍니다.

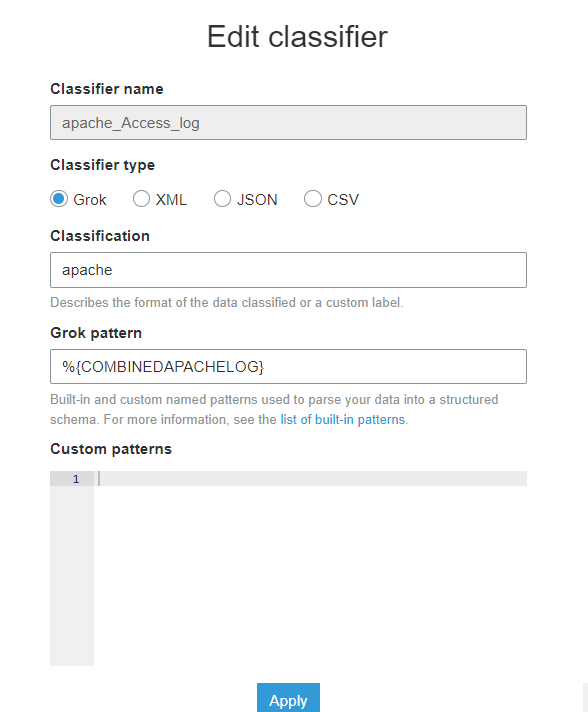
Classifier name은 본인이 원하는 대로 지어주시면 됩니다.
Glue Crawlers 생성하기
아래와 같이 Crawlers 탭에서 Add crawler로 크롤러를 생성해줍니다.

먼저 이름을 정하는 Crawler info부분이 나올 것인데, Tags, description, security configuration....( optional )와 같은 부분에서 아까 만든 Classifler을 Add 해줍니다.

Data stor로 로그가 저장되는 S3의 기본 경로/access_log 를 써주도록 합니다. 나머지는 디폴트 설정이거나 거의 설정할 것이 없습니다.
혹시 모르니 세부정보를 보여드리겠습니다.

그리고 생성한 크롤러를 선택하고 Run crawler을 클릭해 크롤러를 실행시키면 제 기준으로 약 2 ~ 3분 뒤에 실행이 완료됩니다.

위와 같이 테이블이 추가되면 크롤링 작업이 완료되었습니다.
Athena 이용하기
AWS Console에서 Athena로 들어가 글루 크롤러를 작동시킨 데이터베이스를 선택해줍니다.

그리고 쿼리문을 통해 데이터를 찍어보면, 다음과 같이 아파치 로그의 정보가 나오는 것을 알 수 있습니다.

이와 같이 크롤러로 데이터를 정규화하는 경우에는 직접 테이블을 선언해주지 않고 S3 경로에 따라 파티셔닝 되기 때문에 데이터에 null값이 있다면, Athena에서 오류를 일으킵니다. 때문에 데이터에 null이 들어가지 않도록 주의해야 합니다.( 이미 데이터가 들어가 오류가 난다면 log가 있는 s3의 파일/폴더들을 삭제하고, 크롤러를 다시 실행시켜주세요 ) 이렇게 S3와 Athena를 통해 로그 파이프라인을 구축해보았습니다. 요금이 나오기 때문에 사용하신 후 리소스는 반드시 제거해주세요